Script
El script completo que se usará en esta sección esta disponible aquí.
Clasificación Supervisada
Las imágenes satelitáles con propiedades espectrales permiten agrupar o clasificar los diferentes objetos visibles según sus firmas espectrales. Para esto es necesario establecer cuáles elementos se desean clasificar y proporcionar datos georeferenciados que respalden a esos elementos en la imagen satelital. Esos datos se conocen en inglés como “ground-truth”. Esto hace que la clasificación que se hará sea llamada “supervisada”, debido a que se conocen los elementos a clasificar. Las clasificaciones son útiles para la elaboración de mapas sobre el uso de la tierra, cobertura vegetal, o habitats. Además, si se realizan clasificaciones en distintos periodos de tiempo se pueden incluso detectar cambios temporales.
1. Preparar imagen
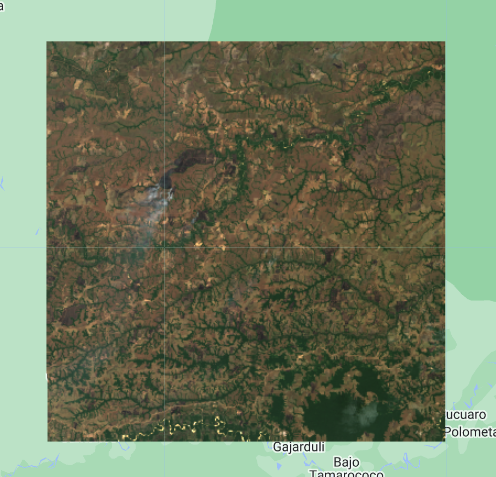
Para el siguiente ejercicio de clasificación supervisada vamos a cargar la colección de Sentinel-2 L2 y seleccionar una imágen que será la que vamos a clasificar.
// Preparar colección de Sentinel-2
var coleccion = ee.ImageCollection("COPERNICUS/S2_SR_HARMONIZED")
.filterDate('2022-01-01','2023-06-06')
.filterBounds(pin)
.filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE',30));
// Lista de IDS
print(coleccion.aggregate_array('system:index'));
// Cargar imagen y visualizar
var imagen = coleccion.filter(ee.Filter.eq('system:index','20220107T150719_20220107T150929_T19NDF')).first();
// Visualizar
Map.addLayer(imagen,{bands:['B4','B3','B2'],min:0,max:2000},'Imagen');
2. Preparar datos
Luego de seleccionar nuestra imagen, debemos preparar los datos que vamos a usar para la clasificación. En este ejemplo, podremos colectar algunos datos visualmente punto por punto, clase por clase. Vamos a considerar las siguientes clases:
- Vegetación
- Agua
- Pasto
- Área sin vegetación
- Área quemada
Seleccionamos algunos puntos (entre 50 y 60) para cada una de estas clases. En este ejemplo usamos un conjunto de puntos relativamente pequeño, ya que en las clasificaciones supervisadas más puntos robustecen los resultados y mejoran la clasificación.
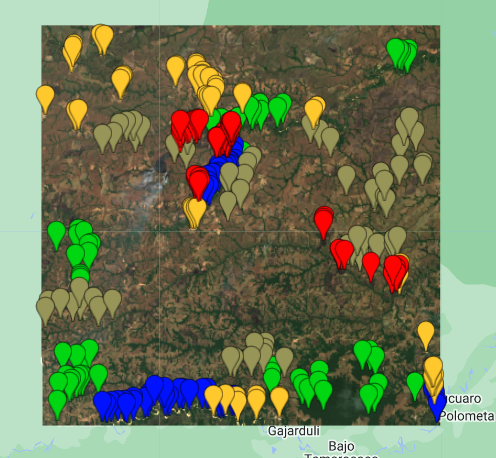
Al crear un conjunto de puntos por clase en GEE vemos que son almacenados en variables diferentes. Pero, los vamos a unir en una sola colección de Features, por eso los cambiamos de Geometry a FeatureCollection, y les asignamos una propiedad en comun, que en este caso la llamaremos “clase” y se le asignará un valor númerico entre 0 y 4 para identificar cada clase.
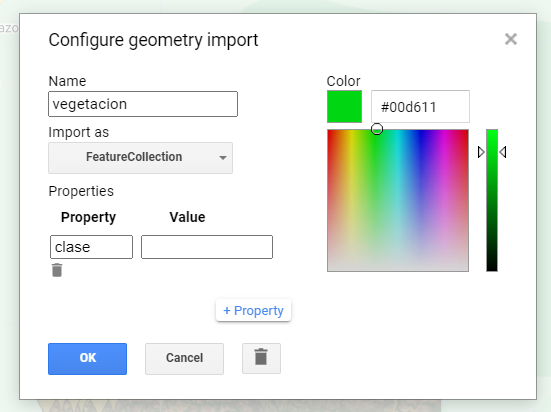
El código será:
// Luego de convertir los puntos de geometrias a FeatureCollection procedemos a unir
// cada conjunto de puntos en un solo grupo diferenciados por la propiedad 'clase':
var puntos = vegetacion.merge(agua).merge(pasto).merge(noVegetacion).merge(quemado);
// Preseleccionar lista de bandas para clasificación
var bandas = ['B1','B2', 'B3', 'B4', 'B5', 'B6', 'B7','B8','B8A','B9','B11'];
// Especificar nombre de propiedad indicando clases.
var propiedad = 'clase';
/*
Las clases son:
0: Vegetación
1: Agua
2: Pasto
3: No Vegetación
4: Area Quemada
*/
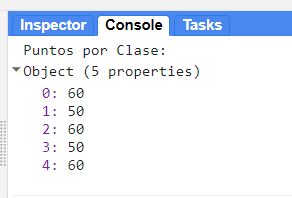
// Imprimir numero de puntos por clase:
print('Puntos por Clase:',puntos.aggregate_histogram('clase'));
Verificamos el numero de puntos por clase, que en su totalidad son 280 puntos.
3. Muestras espectrales + Partición de datos de entrenamiento y validación
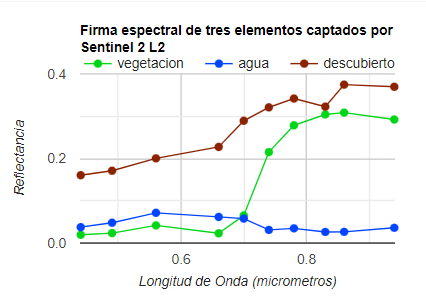
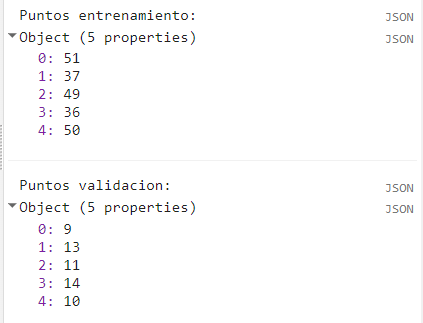
El conjunto de puntos los vamos a usar para muestrear las firmas espectrales, es decir que de cada punto se tomarán los valores de cada banda espectral. Luego procedemos a particionar el conjunto de datos en 80% para entrenamiento y 20% para validación. Para esto aplicamos la función randomColumn, la cual añadirá una columna nueva asignando valores aleatorios únicos entre 0 y 1 a cada clase. Esto es parecido a una indexación. Posteriormente filtramos los valores por encima y por debajo de 0.8 en la columna random, para separar los datos de validación y entrenamiento, respetivamente.
// Muestrear valores espectrales en cada punto
var muestras = imagen.select(bandas).sampleRegions({
collection: puntos,
properties: [propiedad],
scale: 10
});
// Añadir columna con valores aleatorios en cada observación.
// Esto servirá para dividir los datos de entrenamiento y validación
var random = muestras.randomColumn('random');
// Dividir datos entre entrenamiento y validacion.
// Aproximadamente 80% para entrenamiento y 20% para validación.
var fraccion = 0.8;
var entrenamiento = random.filter(ee.Filter.lt('random', fraccion));
var validacion = random.filter(ee.Filter.gte('random', fraccion));
4. Entrenar modelo y clasificar imagen
Luego de tener nuestros datos de entrenamiento, procedemos a entrenar un clasificador que en este ejemplo será Random Forest. Luego aplicaremos ese modelo a nuestra imagen para obtener un mapa clasificado.
// Entrenar clasificador Random Forest con 10 arboles.
var clasificador = ee.Classifier.smileRandomForest(10).train({
features: entrenamiento,
classProperty: propiedad,
inputProperties: bandas
});
// Clasificar imagen con modelo y Visualizar clasificación
var mapa = imagen.classify(clasificador);
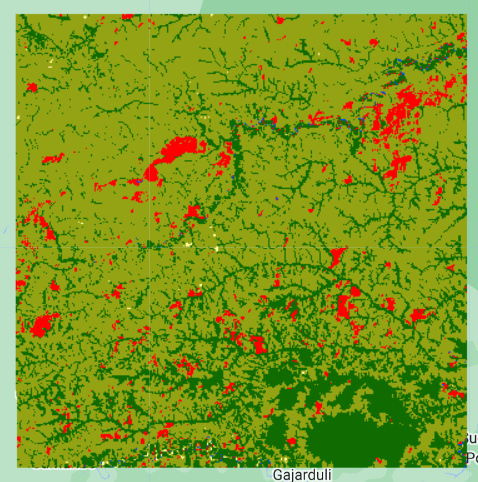
Map.addLayer(mapa, {min: 0, max: 4, palette: ['#106c00','#004dff','#93a313','#fffc9d','#ff0000']},'RF');

5. Precisión de la clasificación
Procedemos a verificar las matrices de error tanto de los datos de entrenamiento como de validación para tener una idea general de como estuvo la clasificación y para mejor interpretación de resultados.
//// Aplicar clasificador sobre datos de entrenamiento y validacion:
var entrenar = entrenamiento.classify(clasificador);
var validar = validacion.classify(clasificador);
// Calcular matrices de error
var errorMatrixTra = entrenar.errorMatrix(propiedad, 'classification');
var errorMatrixVal = validar.errorMatrix(propiedad, 'classification');
print('Error Matrix Entrenamiento',errorMatrixTra);
print('Error Matrix Validacion',errorMatrixVal);
// Calcular precisión total
print('Precision Total Entrenamiento: ', errorMatrixTra.accuracy());
print('Precision Total Validacion: ', errorMatrixVal.accuracy());
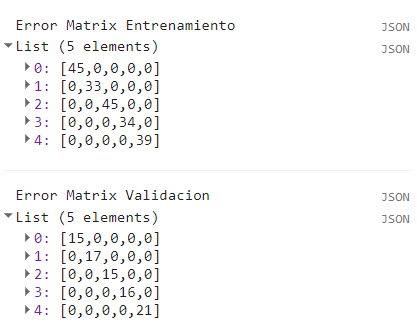
Lo que vemos en las matrices de error es que todos los datos predecidos concuerdan con los datos observados. Esto significa que el modelo fue un 100% acertado. Este valor es debido al poco numero de datos. Ahora, nos interesa calcular la precisión de la clasificación. Para esto se requiere que nos enfoquemos en la matriz de error de validación, que será con la que se compara y se mida la precisión. Existen otros dos términos importantes al hablar de estimaciones de precisión en clasificaciones supervisadas, estos son la precisión del productor y la precisión del usuario. Estas ayudan a estimar la precisión dentro de cada clase.
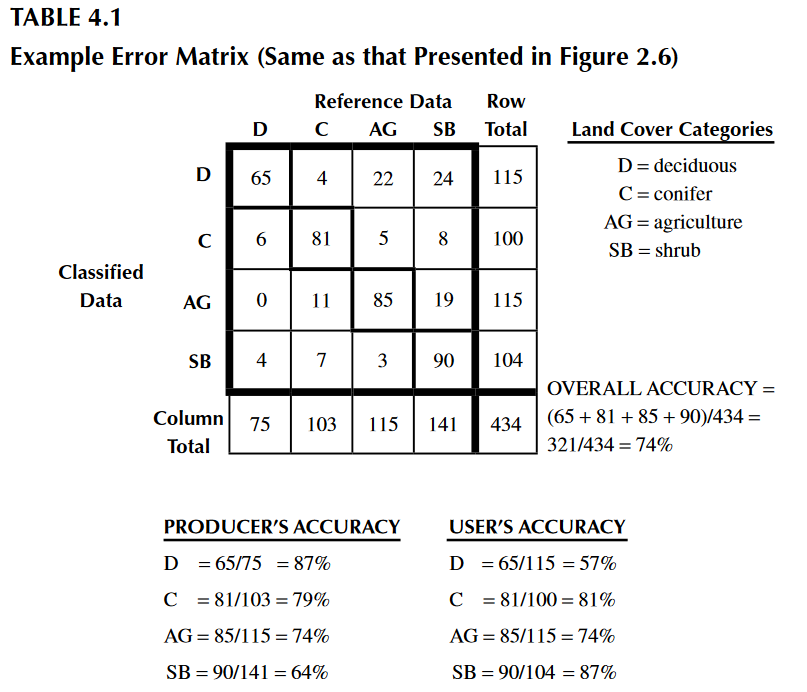
En la imagen de arriba tomada de Congalton & Green (2009), se puede estimar la precisión de la clase “Deciduous” de dos formas: (1) Tomando el número total de unidades de muestreo clasificadas correctamente (65) divididas por el número total de unidades respectivas en los datos de validación (75), esto nos da como resultado una precisión de 87% (Precisión de Productor). (2) Por otro lado, si tomamos el número total de unidades de muestreo clasificadas correctamente (65) divididas por el número total de unidades clasificadas como “Deciduous” (115), tendremos una precisión de 57% (Precisión de Usuario). Esto nos demuestra lo diferentes que pueden ser ambas precisiones. Por lo tanto, en este ejemplo se demuestra que cada precisión estimada tiene su interpretación y hay que ser específico al presentar los resultados de una clasificación supervisada.
Continuando con nuestro ejemplo de GEE, calculamos las precisiones de usuario y productor:
// Precisión de Usuario y de Productor
var producerAccuracy = errorMatrixTra.producersAccuracy();
var userAccuracy = errorMatrixTra.consumersAccuracy();
print('Producer Accuracy: ',producerAccuracy);
print('User Accuracy: ',userAccuracy);
Como obtuvimos una precisión general del 100%, las precisiones por clase también seran de 100%.
Bonus 1: Calcular área
Podemos calcular las áreas de cada clase en nuestro mapa. Para esto hacemos una máscara por valor de pixel (clase), que multiplicamos por el area de pixel usando ee.Image.pixelArea(), esto nos dara como resultado pixeles con valores de área por pixel en metros cuadrados.
// Calcular area
// Usaremos la clase 4 que es area quemada.
var Area = mapa.eq(4).multiply(ee.Image.pixelArea());
// Aplicamos reductor para sumar el area de todos los pixeles
var reducerArea = Area.reduceRegion({
reducer: ee.Reducer.sum(),
geometry: imagen.geometry(),
scale: 10,
crs: 'EPSG:4326',
maxPixels: 1e15
});
// Convertir m^2 a km^2
var areaSqKm = ee.Number(reducerArea.get('classification')).divide(1e6);
print('Area (km^2):',areaSqKm);
Bonus 2: Suavizar
En algunas ocasiones se pueden suavizar las imagenes para lograr clasificaciones menos ruidosos y más agradables a la vista. Aunque no es recomendable abusar de los suavizados, ya que altera un poco las propiedades espectrales de cada pixel, perderemos detalles, y obtendremos precisiones sesgadas al momento de validar. El kernel se aplica sobre la imagen espectral, antes de muestrear los datos en cada punto. En GEE podemos suavizar imagenes usanddo Kernels ee.Kernel. En este ejemplo usaremos un Kernel Gaussiano en una ventana de 3x3 pixeles.
// Suavizar imagenes
//Crear kernel
var kernel = ee.Kernel.gaussian({
radius:3,
units:'pixels',
normalize:false
});
// Aplicar kernel
var imgKernel = imagen.convolve(kernel);
// Muestrear cada punto
var muestras = imgKernel.select(bandas).sampleRegions({
collection: puntos,
properties: [propiedad],
scale: 10
});
// Añadir columna con valores aleatorios en cada observación.
// Esto servirá para dividir los datos de entrenamiento y validación
var random = muestras.randomColumn('random');
// Dividir datos entre entrenamiento y validacion.
// Aproximadamente 80% para entrenamiento y 20% para validación.
var fraccion = 0.8;
var entrenamiento = random.filter(ee.Filter.lt('random', fraccion));
var validacion = random.filter(ee.Filter.gte('random', fraccion));
// Entrenar clasificador Random Forest
var clasificador = ee.Classifier.smileRandomForest(10).train({
features: entrenamiento,
classProperty: propiedad,
inputProperties: bandas
});
// Clasificar imagen con modelo y Visualizar clasificación
var mapa = imgKernel.classify(clasificador);
Map.addLayer(mapa, {min: 0, max: 4, palette: ['#106c00','#004dff','#93a313','#fffc9d','#ff0000']},'RF-Kernel');

BONUS 3: Clasificación no supervisada
La clasificacion no supervisada es un metodo que agrupa en un numero de clases definidas los datos que más tengan parecido entre sí espectralmente. Al ser no supervisado no hay forma de medir precisión, estrictamente hablando.
Realizamos un entrenamiento. Se puede realizar un entrenamiento totalmente no supervisado, el cual tomaría puntos aleatoriamente dentro de un área de interés. Pero también podriamos usar los puntos ya colectados. Luego se crea un cluster usando la función ee.Clusterer.wekaKMeans y se aplican los datos entrenados. Finalmente se aplica el cluster a la imagen.
//var training = imagen.sample({region: %definir%, scale: 10, numPixels: 5000}) // Totalmente no supervisada
var training = imagen.sampleRegions({
collection: puntos, // Con ayuda de puntos
properties: [propiedad],
scale: 10
});
// Creamos un cluster con cinco clases
var clusterer = ee.Clusterer.wekaKMeans(5).train(training);
// Aplicar a imagen
var result = imagen.cluster(clusterer);
// Visualizar
Map.addLayer(result, vis, 'Cluster');