Background on Stratified Random Sampling, Map Validation, & Unbiased Area Estimation
Stratified Random Sampling
There are several different ways to sample an area in order to achieve a representative sample or the landscape and the variations within it. Sample data gathered in CEO can be used for a variety of purposes, including map validation.

Systematic Sampling: observations are placed at equal intervals according to a strategy

Simple Random Sampling: observations randomly placed

Stratified Random Sampling: Using a map to inform the design, a minimum number of observations randomly placed in each category
Stratified random sampling has two key benefits
- Updates map-based areas to increase precision (reduces uncertainty)
- Helps increase chance of having plots in rare classes
We will use stratified random sampling to perform a map validation analysis. You can use different tools, such as Google Earth Engine, to generate the locations of the sample points.
We will use the map you developed in a previous training. This is the 8 class Land Cover product, produced using a 2020 annual median Landsat composite for the input data and Copernicus Global Land Cover reference data.
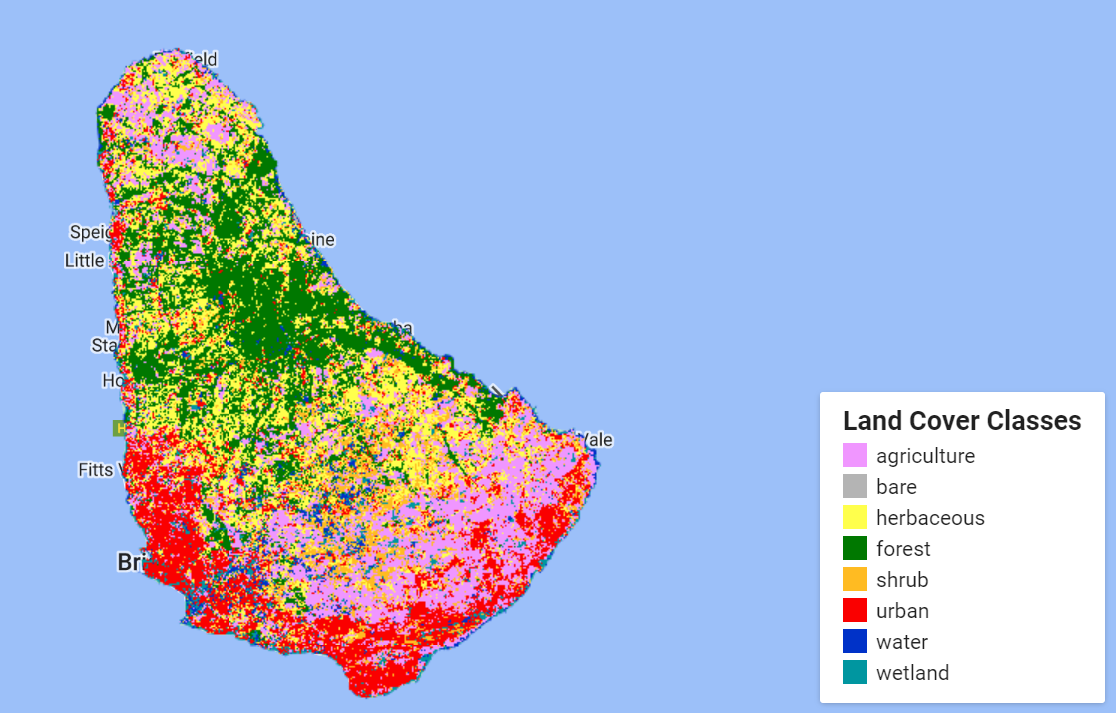
We have pre-calculated approximate pixel counts of the map classes using Google Earth Engine.
| Map Value | Readable Map Class | Pixel Count | % of Total |
|---|---|---|---|
| 1 | agriculture | 109,493 | 22% |
| 2 | bare | 137 | 0.00026% |
| 3 | herbaceous | 103,144 | 20% |
| 4 | forest | 109,823 | 22% |
| 5 | shrub | 53,691 | 11% |
| 6 | urban | 81,729 | 16% |
| 7 | water | 19,143 | 4% |
| 8 | wetland | 22,145 | 4% |
If we had used systematic or random sampling we might severely undersample rare classes and oversample common ones. With stratified random sampling I can put a minimum value on the number of points in each map class, or strata. We have pre-prepared a set of points with 20 in each of the three rarest classes 10 points in the more common classes, for a total of 110 sample points. The stratified random sampling was performed in GEE using this script, which exports a CSV of sample locations ready to be imported into CEO.
Download that CSV file here.
The included samples are distributed within the assigned map strata. 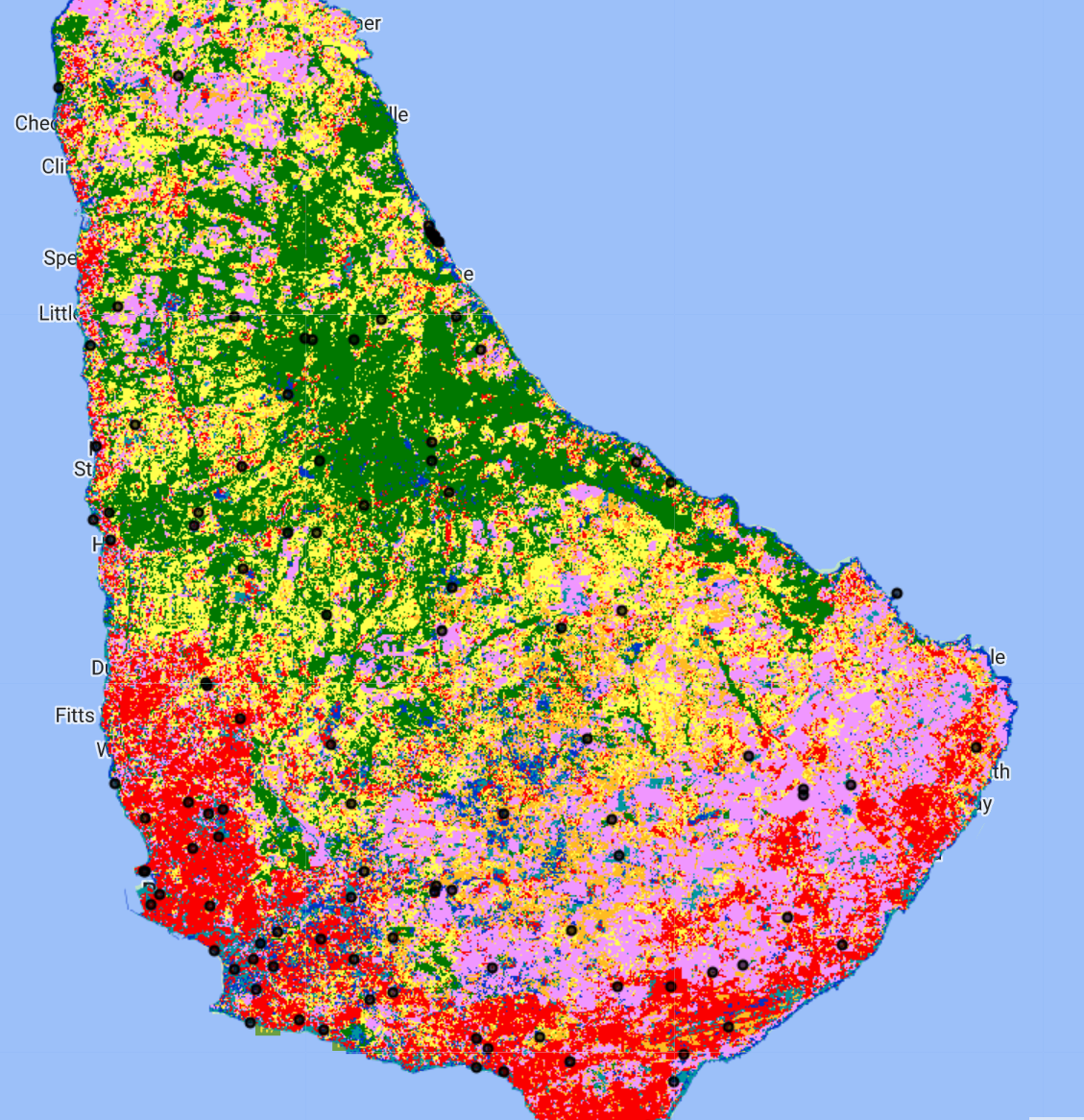
Map Validation
Map validation can be performed by comparing the map classes of representative sample points to reference labels at those locations, which are collected using human interpretation and are considered to be ‘correct’ labels for these points. If the rates of agreement between the map labels and the interpreter reference labels are very high then we can infer the map is a good representation of the mapped characteristics.
Confusion Matrix
We can quantify the accuracy of the map using a confusion matrix (error matrix). The reference data dictates the actual value (the truth) while the left shows the prediction (or map classification). - True positive and true negative mean that the classification correctly classified the labels (e.g., a flood pixel was correctly classified as flood). - False positive and false negative mean that the classification does not match the truth (e.g., a flood pixel was classified as no-flood)
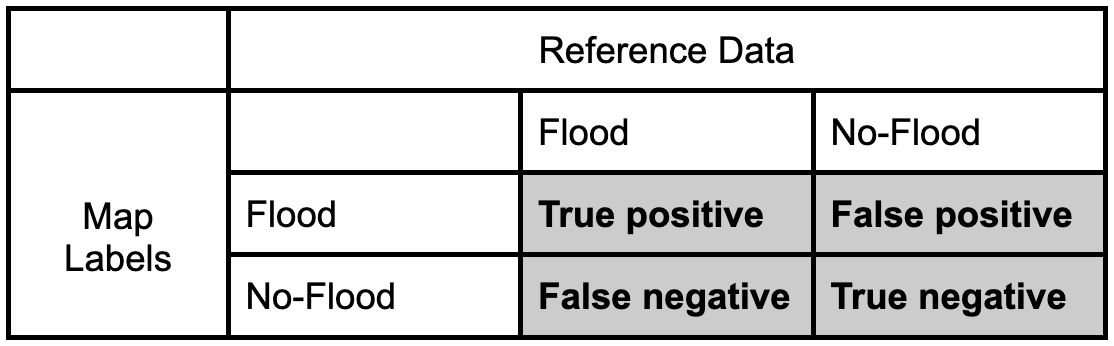
Let’s fill in this confusion matrix with example values if 100 points were collected. 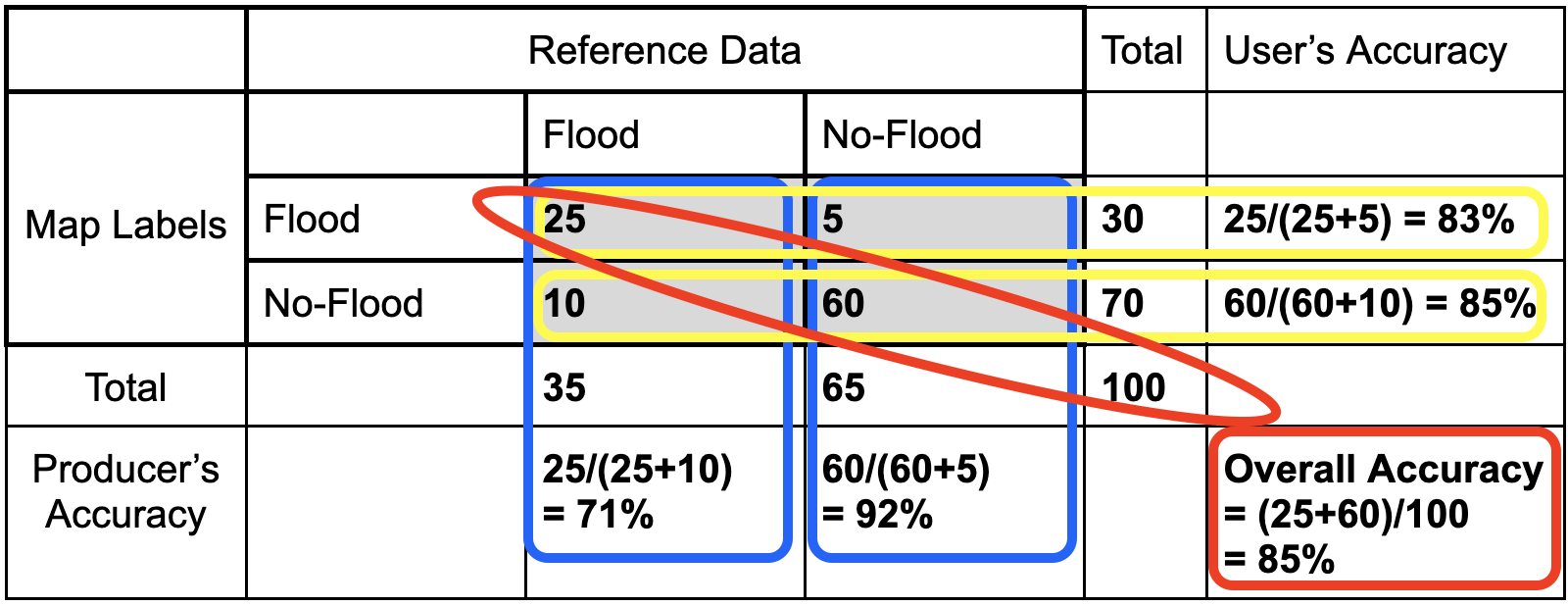
Producer’s Accuracy
- The percentage of time a class identified on the ground is classified into the same category on the map.
- The producer’s accuracy is the map accuracy from the point of view of the map maker (producer) and is calculated as the number of correctly identified pixels of a given class divided by the total number of pixels in that reference class. The producer’s accuracy tells us that for a given class in the reference pixels, how many pixels on the map were classified correctly.
- Producer’s Accuracy (for flood) = True Positive / (True Positive +False Positive)
- Producer’s Accuracy (for no-flood) = True Negative / (True Negative +False Negative)
Omission Error
- Omission errors refer to the reference pixels that were left out (or omitted) from the correct class in the classified map. An error of omission will be counted as an error of commission in another class. (complementary to the producer’s accuracy)
- Omission error = 100% - Producer’s Accuracy
- (Flood) Omission Error is when ‘flood’ is classified as some ‘other’ category.
User’s Accuracy
- The percentage of time a class identified on the map is classified into the same category on the ground.
- The user’s accuracy is the accuracy from the point of view of a map user, not the map maker, and is calculated as the number correctly identified in a given map class divided by the number claimed to be in that map class. The user’s accuracy essentially tells us how often the class on the map is actually that class on the ground.
- User’s Accuracy (for flood) = True Positive / (True Positive +False Negative)
- User’s Accuracy (for no-flood) = True Negative / (True Negative +False Positive)
Commission Error
- Commission errors refer to the class pixels that were erroneously classified in the map. (complementary to the user’s accuracy)
- Commission error = 100% - user’s accuracy.
- (Flood) Commission Error is when ‘other’ is classified as ‘flood’.
Overall Accuracy
- Overall accuracy = (True Positive + True Negative) / Sample size
- The overall accuracy essentially tells us what proportion of the reference data was classified correctly
Unbiased Area Estimation
Often we create classification or change maps to estimate the amount of area that has a certain land cover type or underwent a certain type of change.
Pixel counting approaches simply sum up the area belonging to each class. However, simple pixel counting is not the most precise or accurate way to do this, since classification maps have errors (both small and large) - originating from data noise, pixel mixing, or poor separation of classes by the classification algorithm. Thus, pixel counting will produce biased estimates of class areas, and you cannot tell whether these are overestimates or underestimates.
Sample-based approaches use manually collected samples and statistical formulas based on the sampling design to estimate class areas (essentially scaling up the data collected in samples to the entire area of interest). They create unbiased estimates of area and can also be used to calculate the error associated with your map. These approaches help quanitfy and reduce uncertainty, making the estimates more robust.